
これはデータフロー型コンピュータアーキテクチャの一種を単一チップで実現するもので、しかも多数のプロセッサを直列に接続すれば処理能力を(上限があるにせよ)容易に上げられるといった特徴を持っています。
ピン配置を以下に示します。
RESET* 1 40 Vcc
IACK* 2 39 OACK*
IREQ* 3 38 OREQ*
IDB15 4 37 ODB15
IDB14 5 36 ODB14
IDB13 6 35 ODB13
IDB12 7 34 ODB12
IDB11 8 33 ODB11
IDB10 9 32 ODB10
IDB9 10 31 ODB9
IDB8 11 31 ODB8
IDB7 12 31 ODB7
IDB6 13 31 ODB6
IDB5 14 31 ODB5
IDB4 15 31 ODB4
IDB3 16 31 ODB3
IDB2 17 31 ODB2
IDB1 18 31 ODB1
IDB0 19 31 ODB0
GND 20 31 CLK
IACK*とIREQ*はデータ入力用のハンドシェークラインで、OACK*とOREQ*は出力用のハンドシェークラインです。複数のImPPを使用する場合、OACK*をIACK*に、IREQ*をOREQ*に接続し、ODBxとIDBxをそれぞれ接続すれば、データ転送をImPP同士で勝手に行います。CLKとRESETはすべてのImPPに共通、もちろん電源端子のVccとGNDも共通の接続となっています。
結局、すべて並列に接続することになる四隅のピンを除くと、左側の18本の端子がデータの入力用、右側18本が出力用になっていて、複数のImPPを接続する場合は一番近いピン同士を順番に直列に接続するだけになっています。これほどマルチプロセッサ構成を実現しやすいプロセッサを他に知りません。
内部構成はこのようになっています。
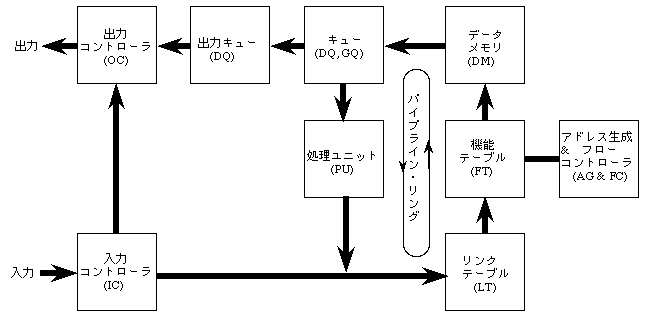
入力から入ってきたデータは、内部のパイプラインリングをぐるぐる回りながら加工され、出力へと送り出されます。自分の担当すべきデータ以外は入力コントローラから直接出力コントローラへ送られます。データ加工の詳細については、時間ができたときに。
さて、ImPPはデータフロー型の非ノイマン型プロセッサであると述べました。すると、先にノイマン型のアーキテクチャがあることになります。一般に、ノイマン型アーキテクチャとして、次の特徴を満足するものをいうことが多いように思います。
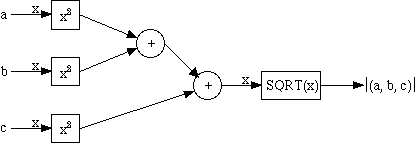
同じことをノイマン型だとどうなるか、アセンブラに近いレベルの疑似コードで書いてみると、たとえばこうなります。
aをレジスタにロードレジスタへのロードなどの状況が異なることも多いでしょうが、概要はこんなものでしょう。乗算回路と加算回路と平方根回路は1回路ずつで、それを各ステップで順番に使っていますが、しかし加算をしているときには乗算回路や平方根回路は遊んでしまいます。上の図の専用ハードウェア演算回路なら、各演算ブロックの遅延時間、つまり演算時間がほぼ同一と仮定して、それをt秒とすれば、4t秒ですべてを求めることができます。tの逆数をクロック周波数とすれば、4クロックで目的の計算が完了します。対して、上の疑似コードで、仮に1ステップを1クロックで求めることができるとすれば、9クロックとなります。しかし、ハードウェア演算回路だとメモリから命令を取り出す必要がまったくありません。ノイマン型アーキテクチャだと、演算以外にメモリから命令を取り出して解釈して演算回路などへ指令を出す必要があります。その分だけ、よけいに時間がかかってしまうかもしれません。もっとも、命令の解釈部分などが多少複雑になりますし、命令を入れるメモリにも多数の部品が必要ですが、演算回路に関してだけなら、上の図のハードウェア演算回路をそのまま実装するより小規模で済みます。同じものを並べればよいメモリ回路は、比較的高密度に実装しやすいでしょうから、実行したい演算が10倍複雑になって命令も10倍ほど必要になったとしても、それほど実装に困難が生じるとは思えません。しかしハードウェアできっちりと配線されたハードウェアで10倍複雑な演算を実行しようとすれば、メモリと比べるとずっと複雑な演算回路を10倍用意しなければなりません。いくら性能を向上しやすいといっても、コストや実現性の点ですぐに限界に到達してしまうでしょう。しかし、逆の視点から見ると、超LSIを用いて多数の演算回路を実装できるようになったとすれば、専用ハードウェア演算回路は回路規模に比例した性能を得やすいといえるかもしれません。ノイマン型の場合、複数の演算回路を同時に効率的に使用するプログラミングがどの程度容易かという問題もありますし、仮に1命令で上の例の3次元ベクトルの大きさを求める専用演算回路とそれに対応した専用命令を用意したとして、ピーク性能が向上するかもしれないけれど、その専用命令を実行するとき以外は活用できないという欠点もあります。多数の各種関数演算回路をいくつもプロセッサに付け加えても、大半が遊んでいる状況では、10倍規模の演算回路を付け加えても2倍くらいしかプログラム実行速度が向上しないかもしれません。
a*aを求める
bをレジスタにロード
b*bを求める
a*aとb*bを加算する
cをレジスタにロード
c*cを求める
a*a + b*bにc*cを加算する
その結果の平方根を求める
さて、非ノイマン型を標榜するには、先に挙げた3項目のどれかひとつに、あるいはいくつか同時に、反していればよろしいということになります。記憶装置に命令列を保持するのは、処理内容を柔軟に変化させるためには実に有利ですから(記憶内容を書き換えれば、異なるプログラムを実行できる)、プログラムカウンタの方をなんとかしようというアイディアがあります。たとえば、複数のプロセッサを同一のメモリシステムに接続し、別のメモリアドレスに書き込まれた命令列を同時に実行するという単純な密結合マルチプロセッサでも、1命令ずつ逐次実行というところに違反していますから、ある意味で非ノイマン型といえないこともないです。もっとも、相互に通信を行う複数のノイマン型アーキテクチャの計算機として考えることもできるので、改良ノイマン型ということもできます。
非ノイマン型アーキテクチャといってもさまざまですが、データフロー型アーキテクチャというのは、プログラムという命令の流れによって処理を行うのではなく、データの流れによって処理を行うというのが特徴なんですが、こういった話は具体例がないとつまらないですから、ImPPに似た抽象的なモデルで考えることにします。このモデルはImPPのアーキテクチャに似ていないことはないですが、それなりに単純化すると共に煩雑なところを隠して高機能にしてありますから、あまりImPPに期待しないように。
データを加工して処理するという視点から、工場のようなモデルを考えます。基本要素としてふたつのブロックを想定します。ひとつは素材としてのデータを管理するデータ置き場……というと感じが悪いですから、資材管理部と名を付けましょうかね。ある種の高機能なメモリシステムをモデル化したものです。もうひとつはデータを演算して具体的な処理をする場所ということで、演算処理部とでもしておきましょう。もちろん、ノイマン型でいうCPUと類似のモデルです。また、このモデルで扱うデータには、ちょっと特別なしかけを用意します。といっても、単なるラベルというか荷札というか、タグが付けられているだけです。タグにはデータの特徴がわかるような名前が書き込まれています。じきに、このタグの役割が重要であることがわかるでしょう。
このようなモデルで、先ほど行った3次元ベクトルの大きさを求める過程を眺めてみます。投入されるデータは(a,
b, c)の3個の実数ですが、とりあえずそれぞれにvect-a0001, vect-b0001, vect-c0001と書き込まれたタグを付けて資材管理部に引き渡しておきます。さて、このモデルが動作を始めると、まず演算処理部が資材管理部に加工すべきデータがあれば渡すように要求します。まずはvect-a0001というタグの付いたデータが資材管理部から送られてきたとします。
演算処理部には、作業手順書が備え付けられています。そこにはvect-a****というタグ(****は任意の4文字と一致することにしておきましょう)が付けられたデータが来たら、その自乗を求めて、その計算結果に新たにvsqr-a****(この****は入力タグの****と同じもの)というタグを付けて資材管理部に送り返すという作業手順が書き込まれています。それに従って、vect-a0001の自乗を求めてvsqr-a0001というタグを付けて資材管理部に送り返します。もちろん、作業手順書にはvect-b****やvect-c****についても同じことを行うように書き込まれているはずです。
さて、資材管理部にも作業手順書が存在します。そこには、データの整理方法に関する手順が書かれています。vsqr-a****とvsqr-b****というふたつのデータ(ここで****は同一の文字)が揃ったら、そのふたつをひとつのカゴに入れて、カゴにtemp-a****というタグを取り付けるというような手順です。vsqr-a****やvsqr-b****やvsqr-c****というタグの付いたデータに関しては、規定のカゴに他のデータとセットにして入れることになっていて、演算処理部から何かデータをよこせと要求されても、そのまま送りだしてはいけないともあります。
結果、vsqr-a0001とvsqr-b0001がひとまとめのデータにされてtemp-a0001というタグを付けられ、演算処理部に送られます。演算処理部の手順書には、temp-a****というデータは、内部の2個のデータを加算して、その結果にtemp-b****というタグを付けて資材管理部に送り返すと書かれています。そのようにして、a2
+ b2にtemp-b0001というタグが付けられて資材管理部に送り返されます。
資材管理部の手順書には、temp-b****とvsqr-c****を組み合わせてカゴに入れ、それにtemp-c****というタグを付けて演算処理部に送り出せるようにしておけという命令があります。それに従い、temp-b0001とvsqr-c0001が組み合わされてtemp-c0001というカゴに入れられて演算処理部に送りだされるときがきます。演算処理部では、temp-c****というデータについては内部の2個のデータを加算してtemp-d****というタグを付けて送り返せという手順があり、それにしたがってtemp-d0001というタグの付いたデータが資材管理部に送り返されます。
資材管理部の作業手順書には、temp-d****というタグの付いたデータには特に何もせず、要求に応じて演算処理部に送り出せと書いてあります。そのまま演算処理部に送りだされたtemp-d0001は、演算処理部の作業手順書にしたがってその平方根を求めて、それにvabs0001というタグを付けて資材管理部に送り返します。資材管理部の作業手順書には、vabs****というタグは計算結果として、演算処理部でなくて外部に発送せよと書いてあります。したがって、そのデータを出荷して、内部には計算を待つデータが何もなくなったので、何か計算対象のデータが送り込まれるまで動作を停止します。
プログラムに相当するものが、資材管理部と計算処理部に備え付けの作業手順書らしいことはわかりますね。ここに表にしてまとめてみましょう。
これが資材管理部の作業手順書です。
| 入力タグ | 動作 | 待ち合わせ/発送 | 出力タグ |
| vect-a**** | なし | 発送可 | そのまま |
| vect-b**** | なし | 発送可 | そのまま |
| vect-c**** | なし | 発送可 | そのまま |
| vsqr-a**** | ペア作成 | 待ち合わせ | ---- |
| vsqr-b**** | vsqr-a****とで構造体に | 発送可 | temp-a**** |
| vsqr-c**** | ペア作成 | 待ち合わせ | ---- |
| temp-b**** | vsqr-c****とで構造体に | 発送可 | temp-c**** |
| temp-d**** | なし | 発送可 | そのまま |
| vabs**** | 計算結果として出力 | ---- | ---- |
次に計算処理部の作業手順書。
| 入力タグ | 演算動作 | 出力タグ |
| vect-a**** | 自乗計算 | vsqr-a**** |
| vect-b**** | 自乗計算 | vsqr-b**** |
| vect-c**** | 自乗計算 | vsqr-c**** |
| temp-a**** | 対のデータの和を求める | temp-b**** |
| temp-c**** | 対のデータの和を求める | temp-d**** |
| temp-d**** | 平方根を求める | vabs**** |
以上のふたつの表が、このモデルのデータフロー型計算機のプログラムに相当するものです。上記の文章の説明を、もう一度この表を見ながら検討してみてください。きちんと計算できますでしょうか。
さて、今までの説明では、タグに4桁の数字が付いていました。先ほどの説明では、3次元ベクトルの大きさの計算をひとつだけ行っていました。仮に、ほぼ同時に5個のベクトルについて大きさを求めたくなったとします。すると、vect-a0001だけでなくvect-a0002とかvect-c0005とかいった、数字の異なるベクトルの要素が15個、ほぼ同時にこの計算機の資材管理部に投入されます。それでも、数字の部分のパターンマッチによって、5個のベクトルのそれぞれの中間計算結果が混ざったりせず、きちんと5個の出力が得られることがわかります。さらに、計算処理部はvect-a0001を処理してからvect-b0001を処理するというような、特別な順序で計算を実行する必要がないことがわかります。資材管理部から送られてくるデータが任意の順序でも(待ち合わせをしているデータは送られてきませんから)、最終的には正しい計算結果を得ることができます。
ノイマン型のアーキテクチャだと、CPU内部にコンテキストを持ちます。データ処理の時系列に厳密に縛られてしまうのです。たとえば、割り込みとか何かを用いて、ベクトルの大きさを求めるプロセスを5個、平行して実行させようとしたら、大変なことです。プロセス切り替えごとにプログラムカウンタやレジスタなどの内容を入れ替えたり、スタック領域もそれぞれ移しかえたり、コンテキストを切り替えるのに大騒ぎになります。
ところが、ここで扱ったモデルのデータフロー計算機では、5個のベクトルの大きさを、それこそ資材管理部の気分で非決定的に任意の順序で求めていくことができます。この違いは何かといえば、直前の計算結果によって計算処理部に影響が残ることがいっさいないという点にあります。このモデルの計算処理部には切り替えるべきコンテキストが存在しないのです。資材管理部からタグ付きのデータを受け取って、それを処理して資材管理部に送り返してしまえば、また最初の白紙の状態に戻るだけという点が、ノイマン型のプロセッサとの違いです。ノイマン型ではプログラムカウンタの指している命令をメモリから読み出して、その命令を実行した後、プログラムカウンタの内容がインクリメントされています(あるいは分岐命令で特別な値に書き換えられている)。突然、なんらかの理由でプログラムの流れと無関係に特定の命令を実行せよという指令を受け付ける場合(割込みに相当します)、プログラムカウンタを含むコンテキストを退避させておかないと、後でもとの状態に復帰できません。データフロー型の場合、演算処理部にも、資材管理部にも、プログラムカウンタは存在しません。コンテキストが含まれないのです。しかし、データ処理はそれなりにきちんと遂行されます。コンテキストはどこに行ってしまったのでしょうか。
それはデータに結び付けられたタグに書き込まれています。プログラムカウンタがプログラムの流れの中の次に実行する命令のアドレスを指しているように、データに付属のタグの内容がデータ処理の流れの中のどの段階にあるのか、指示しています。ちょうど、ノイマン型アーキテクチャで命令をひとつ実行するごとにプログラムカウンタの内容が書き換えられる(たいていは+1される)のと同じように、このモデルのデータフロー型アーキテクチャではデータ処理が1段階進むごとにタグの内容が書き換えられています。タグこそが、プログラムカウンタの役割をはたしているのです。データとともにコンテキストが存在し、プログラムの流れによってデータが加工されるのではなく、データが流れていくと共にデータが加工されるイメージが、データフロー型アーキテクチャの本質です。
ついでに、3次元ベクトルの大きさを求めるだけでなく、別の、たとえば7次までの多項式を求めるように作業手順書を書き直すことを考えてみます。多項式が求まれば、適当に係数と定義域を選ぶことで、sin(x)のような三角関数なんかの近似値を求めることができますね。やはり中間段階のデータにユニークな名称のタグを付けて、それぞれに乗算や加算の処理を割り当てていけばよいのですが、注意すると、3次元ベクトルの大きさを求める作業手順にはいっさい手を触れずに、新たな作業手順だけを書き加えればよいことがわかります。ノイマン型のプログラムの雰囲気では構造化されたプログラムにはなっていませんが、作業手順のモジュール化はできそうで、発想にさえ慣れてしまえば、一種のプログラミングはそんなに難しくないかもしれません。ノイマン型とは異なるアーキテクチャでもプログラマブルなものが存在するのですね。データフロー型アーキテクチャの発想に沿った高級言語というのはどのようなものか、考えてみるのも楽しいかもしれません。
おっと、ちょっと横道にそれました。モデルに戻って、多数のデータに対して多種類のデータ処理を実行する状況を考えてみます。もちろん、計算処理部は大忙しでしょう。こんな状況で、LSI技術が発展して多数の回路部品を使用できるようになってきたとします。プログラム、つまり資材管理部と計算処理部の作業手順書をあまり書き直さずに、データ処理能力を向上させる方法があるでしょうか。
計算処理部に関しては、簡単に向上できます。まったく同じ計算処理部を追加して、その追加した計算処理部にも同じ作業手順書をコピーして使用させればよいのです。ふたつの計算処理部は、それぞれ勝手に独立したタイミングで資材管理部に計算すべきデータを(タグと共に)渡すように要求します。それぞれ指示された計算を行った後、計算処理部の間ではまったく相互作用を行うことなく、資材管理部とデータの送受信を行うだけです。これは、渡されたデータを処理するのに、それ以前の計算の影響が計算処理部の中に残っていないから可能になることです。コンテキストは計算処理部の中ではなくてデータの側にしか存在しないため、もともとひとつの計算処理部で計算を行っていたときでも、資材管理部の気紛れで送られてきたデータを単に処理するだけで良かったことからの自然な帰結です。ふたつの計算処理部でなく、仮に10個の計算処理部が並列して働くことだって、まったく問題ないのです。このとき、プログラムである作業手順書はまったく書き直されていないことに注意してください。シングルプロセッサでも、ふたつの計算処理部によるマルチプロセッサでも、30個の計算処理部から構成されるマルチプロセッサでも、まったくおなじプログラムが動く。これはノイマン型ではそう簡単に実現できないデータフロー型アーキテクチャの、このモデルの特長です。投入できるハードウェアリソースの規模に比例して、自然と性能向上が図られる。スケーラブルコンピュータの理想の姿がここにはあります。
多数の計算処理部が並列動作するようになると、資材管理部の方も忙しくなります。多数の計算処理部とのデータのやりとりと、その際に必要になる複数のデータの待ち合わせの管理の作業の時間を短縮できないと、せっかく増設した計算処理部の一部が遊んでしまいます。計算処理部と同じように、資材管理部も増設して性能を向上できないでしょうか。
実は、資材管理部の方は簡単に増設して性能を向上させることが、このモデルでは困難です。というのは、データの待ち合わせがあるからです。単にタグを付け替えて計算処理部に送り返すだけの仕事なら、計算処理部の数に比例した資材管理部の増設を行い、特定の資材管理部の計算すべきデータの在庫が満杯になりかけたら、計算処理部とのデータの受け渡しの合間をぬって別の資材管理部にデータを横流しするような制御を行えば、それなりになんとかなりそうです。しかし、データの待ち合わせが生じる場合、特定の資材管理部に送りつけられたデータの片割れを探すのに、すべての資材管理部に問い合わせをしなくてはなりません。それも、そのデータが計算されて用意されるまで何回も。資材管理部が4個くらいになってくると、互いに問い合わせる待ち合わせデータの情報のやりとりだけで処理能力が飽和してしまいそうです。
これを防ぐには、まったく同じ作業手順書を複数のモジュールで使用するというのを諦めなくてはなりません。特定の種類データの待ち合わせを特定の資材管理部で必ず実現するように、作業手順書を書き換えるなら、なんとか複数の資材管理部を並列動作させられます。たとえば、外部から投入されたデータを最初に処理するのは第1資材管理部と第1計算処理部が担当する。そこである程度の処理がなされた後には第2資材管理部にデータが送られ、第2計算処理部とともにデータ処理を行う。さらにその成果を第3資材管理部に送り……という具合です。タグの一部、あるいは作業手順書の一部フィールドの意味として、自分のところで処理を続けるか、どの資材管理部に送るか、というような形の指示を追加するようにすれば、このような作業分担を実装するハードウェア上の仕組みはなんとかなります。ただし、各資材管理部の作業手順書が異なってしまいます。これは、プロセッサの数が変更されると、プログラムを書き換えなくてはならないということにつながります。アセンブラ的な方法でプログラム開発を行うと、ハードウェア構成の変更に対応するのは相当に面倒そうです。データフロー型アーキテクチャに沿った高級言語というのが存在するなら、コンパイラオプションでコードを動作させるハードウェア構成を指示してやれば、最適化したオブジェクトを自動作成してくれてもよさそうですが、はたしてそのようなものは開発されているのでしょうか。ただ、このような静的分析によって自動負荷分散を行うのは困難かもしれません。
ともあれ、モデルからImPPそのものの話に戻りますと、モデルの資材管理部と計算処理部とのデータをやりとりする部分がImPPではパイプラインリングと呼ばれる部分に相当します。あ、ずっと上の方にあるImPPの内部構成図を参照してください。データに付属するタグは、パイプラインリング中でも何回も書き直され、ビット幅も場所によって異なります。タグは文字列ではなくて2進数表現の数値になっていますよ。
ImPPにはリセット時にID番号がロードされ、多数を直列に接続して並列動作させる場合にも、互いに区別できるようになっています。ImPPの外部とのやりとりで使用されるデータにもタグが付けられていて、そのタグの一部のフィールドにImPPのID番号が書き込まれています。それで、入力コントローラが外部からデータを受け取ったときに、自分が処理すべきデータか(タグのIDフィールドの内容と自分のID番号が一致したとき)、別のImPPが処理すべきデータか判別して、別のImPPが処理すべきものだとわかればすぐに出力コントローラに渡します。その他の入力タグのフィールドを調べると、自分の処理すべきデータとして取り込んだものの中にも、本来の計算対象としてのデータか、各種テーブルに登録すべきデータか(モデルでいう作業手順書のコード)などがわかり、それなりの動作を行います。さらに本来の計算対象としてのデータなら、入力タグを調べればデータの種類がわかり、どのようなタグの貼り替えが行われていくかも決まります。おそらく、何回かパイプラインリングを回されながら、場合によってはデータメモリで他のデータと待ち合わせを行い、処理ユニットで演算加工が加えられて、出力コントローラから別のImPP(や外部回路)へ出力されることになるでしょう。これが、ImPPの計算の概略です。
ソフトウェアサポートでは、アセンブラやローダに相当するものと、シミュレータが用意されていたように思います。ただし、高級言語的なものがあったとは聞いていません。どこかで実験的に作成したかもしれませんが。
ついでに、このチップを普通のコンピュータのバスやメモリに接続するインターフェース用LSIとして、このuPD9305が後で発表されました。MAGICという通称が付けられています。ImPPはImPP同士でデータを受け渡すためにあるようなものですから、メモリから命令やデータを取り出してImPPのふりをしてImPPにデータを与えたり、ディジーチェーンの最後のImPPからImPPのふりをしてデータを受け取ってメモリに書き込むような制御回路が必要です。それを1チップに集積したのが、このLSIです。

画像処理などの専用コンピュータに、という応用が考えられていましたが、よほど慣れないとプログラムを作成しにくいというデータフローアーキテクチャ一般の欠点のほか、普及する前に汎用の32 bitプロセッサの高性能化によって能力が追い抜かれ、出番をなくしてしまった感があります。NECのワークステーションの画像処理装置などに使われていました。
使用例をひとつ。PC9801のC-Bus用の画像処理ボードです。ホロニクス製。

上部左に4個並んでいるのがuPD7281で、その下にuPD9305がある。上部右側に4枚並んでいるモジュールがデータメモリで、18 bit構成の512 KWord分ある。
Return to IC Collection